Lecture Maschine Learning 2 - Advanced Methods
Warning
This document is part of my exam preparation and therefore still work in progress. Handle with care!
Semi-Supervised Learning
The higher the Vapnik-Chervonenkis-Dimension and therefore the capacity of a classifier the more samples are needed for training.
Definition: For Semi-supervised Learning some data is labeled, but most is not.
Motivation: Labeled Data is hard to get and expensive, while unlabeled is easy and cheap.
- Smoothness Assumption: The label for two data instances that are “close” to each other and in a dense cluster should be similar.
- Cluster assumption: Data instances in the same cluster tend to have the same label.
- Manifold Assumption: high dimensional data can be represented by a lower-dimensional representation. Learn More
Semi-supervised learning extends
- Supervised learning with information about the data distribution
- Unsupervised learning with information and restrictions about the cluster distribution
Goal is to get a better hypothesis than without semi-supervised learning. This means be better than unsupervised learning with all unlabeled data and supervised learning with labeled data.
Self-Learning (or Self-Training, Self-Labeling, Decision-directed learning)
- Train with labeled data
- Predict unlabeled data
- Add unlabeled data with predicted labels based on
- Confidence of the prediction (if over threshold)
- All Data
- Weighted with the confidence of the prediction (must be supported by learner e.g. AdaBoost)
- Go to Step 1
Can wrap most supervised algorithms. The issue is that early but wrong decisions influence the whole process negatively. (Solution: Relabel data if confidence is under threshold)
Co-Learning Blum and Mitchell (1998)
- Split feature vector into two disjunct feature spaces (“Feature Split”). Ideally these are naturally splittable
- Train classifier on each labeled feature subset
- Predict data label
- Add data with high confidence to the respective other data set
- Use democratic voting for more than two classifiers
- Only when a threshold is reached
- Weighted based on confidence
- Retrain model(s) with the new data
Fake Feature Split to split data that is not “naturally” splittable Multi-View Learning: No split, but voting of multiple classifiers (similar to Ensemble) CO-EM use all data, use classifier probability to weight the data.
Generative Probabilistic Models
Generative Probabilistic Model try to estimate the distribution of data based on the class. Learning in this context means iterativly optimizing the parameter-set which is different depending on the choosen distribution. (e.g. for Gaussian with the a-priori class probability, the mean, and the covariant matrix).
Expectation-Maximization (EM) Algorithm
- Define model based on the labeled data
- E-Step: Predict class for unlabeled samples (soft labeling)
- M-Step: Maximize prediction by updating the parameter vector with all (including newly labeled data)
This is a subset of self-learning and will converge to a local (not global!) maximum. If the fundamental assumption of the underlying distribution is wrong, then this will fail, too. Expectation-Maximization can be extended by Gaussian Mixture per Class or weighting unlabeled data with a factor below one.
Low-Density Separation
SVM goal according to Vapnik: Split with maximum margin to all classes and split in a low-density region.
Basics SVM
- Loss Function : distance between hypothesis and label.
- Approximation of Loss: with Quadratic Loss Function.
- We are interested in the real error , that can only be approximated, since the actual distribution of the data is unknown. Goal is to find a Hyperplane that maximizes the margin.
Lagrage
By using the Lagrage Method we can solve this optimization problem
- Lagrage Method
- most , only the support vectors have and therefore influence the optimization
- therefore is a linear combination of the support vectors
Soft Margin
Extend support vector machines for use in nonlinearly separable data with Soft Margin. Soft Margin allows some misclassifications.
- with Soft Margin: with the slack variables and the regulazation parameter. This is constrained by and (meaning mostly correct classification)
Optimization Problem for Semi-Supervised learning
By introducing the Hinge Function we can reformulate the optimization problem to . Introducing a second term for optimizing for unlabled data (Bennett and Demiriz, 1999). Solving this optimization problem will lead to a seperation, were there are no (or little ) data. So in an area with low density.
For imbalanced data sets, most Data might be classified as one class. This can be solved by an additional constraint , meaning that the number of labels for both classes should be similiar.
- Train SVM with labeled data
- Soft Label unlabeled Data
- Iteratively use the optimization formula to relabel the unlabeled data point while increasing loss () of unlabeled for each step. Relabeling is based on the switchability of a data sample. Meaning only if the loss after the switch is less than before switching is done.
Interprets the distance between seperation and data point as a probability. with The new optimization problem uses the Entropy for regularization
Conclusion
- Optimization is more complex due to the optimization problem being non-convex
- Can have local minima
- Can fail if the base assumption of “separation is in the low-density area” is untrue Source: (Bennett and Demiriz, 1999)
Active Learning
Learning Machine selects some extra data that is labeled by an oracle (e.g. a human annotator as a “human in the loop”). There are different types of approaches as described by Settles (2009). Active Learning builts both a labeled data set and a learning machine with each iteration.
Query Synthesis The learning machine generates a synthetic query (feature vector) and gets a label from an oracle.
Selective Sampling (Atlas et al., 1990). The learning machines select samples from a data stream, minimizing the cost of both “seeing a label” and classifying correctly.
- Define Insecurity Region
- Monitor Samples
- Query samples that are in the insecurity region
- Learn & Reiterate
Pool based Sampling (Lewis and Gale, 1994). The learning machine draws queries based on some informativeness measure.
- Measure informativeness/insecurity for all samples and rank them
- Query human/oracle for top k samples
- Learn & Reiterate
Insecurity Measures
The learning machine should select the data points, where it has the highest uncertainty. This means were the prediciton is least confident.
Another measure can be to minimize the margin:
Entropy can also be used:
Version Space Learning
Set of all consistent (meaning not contradicting the data) hypothesis subset of the hypothesis space excluding the inconsistent hypothesis. The idea is to find the hypothesis that reduces the number of consistent hypotheses most.
Query-by-Committee (QBC) (Seung et al., 1992)
1. Train multiple classifiers (in the paper called students)
2. Selective Sampling
1. Classify monitored samples
2. Retrain if contradiction & Iterate
2. Pool based Learning
1. Measure the contradiction measure for all samples & rank them
2. Query for top k samples
3. Retrain & Iterate
Again Insecurity can be measures with Bayes Rule or via Entropy
Problem here is that outliers might be included. This can be solved by adding a Term for the density.
Spiking Neuronal Network (SNS)
Try to model Neurons more realistically. A biological neuron consists of Dendrites (inputs), Soma (summation), Axon (output) and synapses (connection). Neuroscience can be similar to Deep Learning. Marblestone et al. (2016) theorizes that humans learn supervised in the Cerebellum, unsupervised in the cortex, and reinforced in Basal galinga and therefore the brain optimizes diverse cost functions. Synapses transform spikes into a current (Post-Synaptic Potential, PSP)
Synaptic Plasticity
Depends on the timing of spikes. Learning happens on long-term plasticity changes (short term is mostly for network stabilization) Presynaptic cell spiking before the postsynaptic cell is causal and will lead to Long-Term-Potentiation (LTP). Increasing the weight of future spikes but decreasing with time.
If the opposite happens, this is deemed to be acausal and leads to Long-Term-Depression (LTD). Decreasing the weights but increases with time. (Markram et al., 2011)
Hebbian Rule (Hebb, 2005): “Neurons, who fire together, wire together. Learning is local and incremental.
Abstraction Levels
Different abstraction levels lead to different models. Regular Neuronal Networks are based on the computational properties while spiking neuronal networks model neurons at an electrical level.
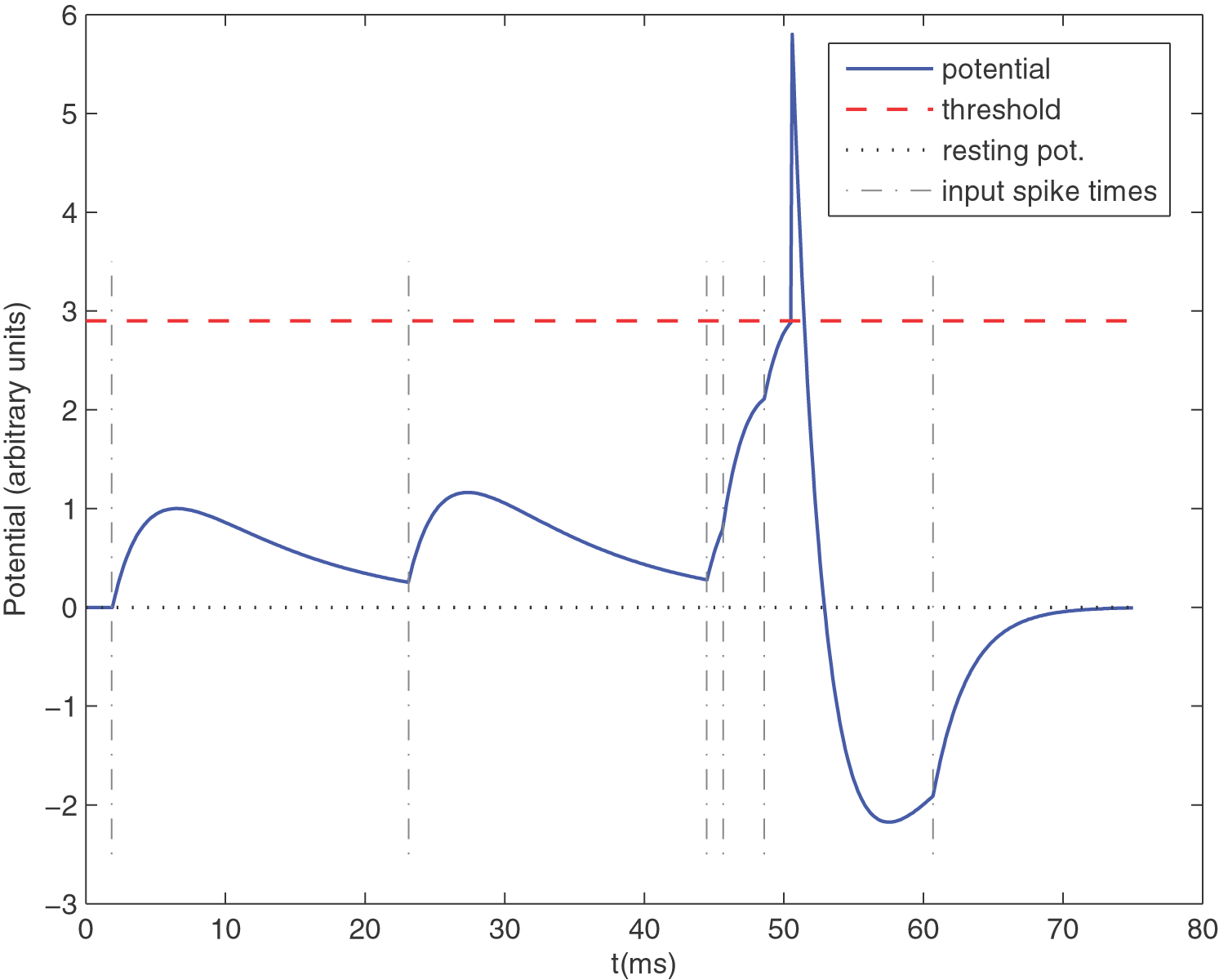 Leaky Integrate-and-Fire (LIF) neuron with 6 spikes shown by dashed vertical lines. Shown is the membrane potential (Masquelier et al., 2008)
Leaky Integrate-and-Fire (LIF) neuron with 6 spikes shown by dashed vertical lines. Shown is the membrane potential (Masquelier et al., 2008)
Parameters are:
- Threshold (red dashed line)
- Resting Potential (grey dotted)
- Leak (membrance time constant)
- Refractory period , were the neuron cannot fire
Models include
- Integrate-and-fire model (Abbott, 1999) uses capacitor and resistor.
- Hodgkin-Huxley (Hodgkin and Huxley, 1952) focuses on realism by adding potassium and sodium concentration terms
- Leaky Integrate and Fire (Abbott, 1999) additionally uses a gate with the Membrane Potential, the Resting Potential, the membrane potential,
- Izhikevich’s neuron model (Izhikevich, 2003) compromises between biological plausibility and computing time. Can be tweaked for different dynamics
- Spike response model (Jolivet et al., 2003) is a generalization of the leaky integrate-and-fire model: with the last spike time, the response to own spikes, the response to incoming spikes
Neural Coding
- Rate coding: Spike rate computed over discrete time intervals. Inefficient and slow computing Analog Model
- Binary coding: After firing, the neuron is in the on (1) state for a given time
- Gaussian Coding for neurons with spatial positions, fitting gaussian on the spike rates
- Synchronous coding encodes information in relation to reference time. Not robust to noise or delay.
- Temporal Coding
- Time-to-first spike
- Rank order coding
- Correlation coding of spatio-temporal (time & location) patterns.
Synaptic Plasticity Rules
These are observed in the brain.
Spike-timing-dependent (STDP)
Weight Update with the pasticity curve of
with the maximum and the minimum weight change, the time constant for
- (Anti-) Hebbian Learning: with for Hebbian and for anti-hebbian
Rate-based
Using a Function for adding rates together: . Mapping the rate via some threshold to eighter “ON” or “OFF”. Common choices for include (Hebbian), , (Gated) … But can also be used as an analog neuronal network
Voltage-based
, weight update depending also on post.synaptic voltage (biologically plausible) (Clopath and Gerstner, 2010)
Reward-Based
Weight update depends additionally on neuromodulator like Depomine, Serotonin, Acetylcholine or Norepinephrine. Reward is released to all neurons (in a region). It is unclear which one contributed to the rewared behavior.
Structural Plasticity
Changing the structure of synapses by destroying or adding them.
Learning for Spiking Neuronal Networks with Backpropagation
Formalize Spiking networks as binary recurrent networks, with discrete time intervals.
Backpropagation Rule for Spiking Networks
with the Input Spike , the derivative of the activation function, the Membrane Potential , the Error
Problems and Solutions
- as a Heaviside (step) function is not differentiable Use surrogate gradients (similar but differentiable functions) (Neftci et al., 2019)
- Time dynamics not taken into account Eligibility traces, use convolution “Eligibility trace” instead (Zenke and Ganguli, 2018)
- Error symmetric feedback Feedback alignemnet
- Synchronous forward/backward steps Local error computation to approximate the gradient (Kaiser et al., 2020)
Unsupervised Learning
- Initialize a dense network with random weights
- Inhibit all neurons except one
- Assign label of most active class to neuron
95% on MNIST (Diehl and Cook, 2015)
Supervised Learning by Associative Learning
- Initialize a dense network with random weights.
- Force spike with teaching signal
- Remove teaching signal to evaluate
Reinforcement Learning with SPORE
- Reward-based structure changes
- Temperature term controlling the exploration (Kaiser et al., 2019)
Variations of Spiking Backgropagation
- Superspike (Zenke and Ganguli, 2018)
- e-prop Bellec et al. (2019)
- DECOLLE (Kaiser et al., 2020)
Hardware
- Neuromorphic chips are special hardware for the sparse connections
- Neuromorphic vision sensor output changes instead of images
- Braitenberg vehicles have some kind of intelligent behavior by using simple (4-10) neurons
Deep Belief Networks (BN)
A Deep Belief Network is a class of neuronal network, whose goal it is to probabilistically reconstruct its inputs. They are composed of multiple layers of stochastic latent variables, having binary values. It is identical in structure to a Multilayer-Perceptron (MLP). It can be seen as a stacked Restricted Boltzmann Machine (RBM) where the hidden layer of one is the visible layer of the next RBM above. Use cases include identification of documents by feature compression, representation of time and space (using windowing technique) for speech detection, trajectories, or Motion Capture.
Explaining Away Problem
The Observation of a cause, that explains an effect, will lead to other causes being less likely. By observing the common effect, the causes are dependent. Learn more
Restricted Boltzmann Machines
Restricted Boltzmann Machines are Neuronal Networks consisting of one hidden layer with the restriction of having no connections between neurons of the same layer.
We introduce the Energy of a configuration
with the binary status of the visible unit, the binary status of the hidden unit, the weights between the two units. This formula excludes biases of the neurons
Contrastive Divergence (CD)
With Contrastive divergence (Hinton, 2002) training of RBMs ist faster.
- Input training vector at visible layer
- Calculate the binary status of the hidden layer (parallel for all neurons) and set the neurons accordingly
- Reconstruct the visible layer by using the hidden layer
- Iterate Steps 2 and 3 times (this is called CD-k, e.g. )
- Update the weights accordingly to with the learning rate
Deep Nets
- Idea: Train each layer separately, starting from the input layer and using the previously trained layers.
Contrastive Wake-Sleep
Introduced by Hinton et al. (2006).
- Wake Phase: Use Input to create a Hypothesis by training the weights of the generative model.
- Sleep Phase: Use the generative model and update the weights of the classification model.
Learning Strategy for Discrimination
- Learn each layer greedily with Contrastive Divergence
- Fine-Tune network with wake-sleep on the pre-trained network
- Add layer for Classification
- Use Backpropagation with labeled data to learn weights
- The RBMs act as feature detectors, the last layer acts as a local search
Convolutional Neuronal Networks
Check out my blogpost with an overview on this topic.
Markov Logic Networks
Markov Logic Networks (MLN) combine first-order logic with probabilistic graphical models. It was introduced by (Richardson and Domingos, 2006). It is a first-order knowledge base with a weight attached to each formula.
Markov Networks
Markov Networks model the joint distribution of a set of variables. They consist of an undirect graph, for the correlation between random variables. Compare this to Bayesian networks, which are directed acyclic graphs and represent the conditional dependencies between variables. For Markov Networks, you can calculate the joint density by factorizing over the potential for each clique in the graph. with
This can be rewritten to the log-linear model
with the binary feature of the clique , and the weight
- Hard Constraints, if this rule is violated the world is impossible
- Soft Constraints, if this rule is violated the world gets less likely Allows us to calculate the overall probability of a world
Inference
A Markov logic network is a set of pairs (, ), where is a formula in first-order logic and is a real number. Together with a finite set of constants , it defines a Markov network as follows: 1. contains one binary node for each possible grounding of each predicate appearing in L. The value of the node is 1 if the ground atom is true, and 0 otherwise. 2. contains one feature for each possible grounding of each formula in . The value of this feature is 1 if the ground formula is true, and 0 otherwise. The weight of the feature is the wi associated with in .
For Inference, the goal is to find the condition of the world with the highest probability (given some evidence). Common approaches are optimizing the Maximum a-posteriori (MAP) or most probable estimate (MPE).
(weighted) MaxSAT solves as many (weighted) formulas as possible.
Other Questions can be “How likely is this new formula?”, approached with the Markov Chain Monte Carlo (MCMC) or “How likely is this formula given this other formula?” using both Knowledge-Based Model Construction (KBMC) and then MCMC
Learning of the Model
Parameters
Find the weights that are most likely to generate the data we see Maximum likelihood Approach, solved with e.g. gradient descent
Graph Structure
- Start with given knowledge base
- Iterate
- Change Operator, Delete/Add, Negate …
- Train Parametes
- Evaluate
- Search for new candidates to change and iterate starting with step 2
Safety and Security
Check out my blogpost with an overview on Safety and Security for Neuronal Networks.
Model-based Reinforcement Learning
Markov Decision Process (MDP) is the formal description of a sequential decision-making problem. It consists of
- a finite set of states . A state is a complete description of the world while an observation is partial.
- a finite set of actions
- a state transition probability matrix, meaning a matrix containing the probability of going from state to state given an action
- a reward function, describing the quality of the action . For reinforcement learning goals must be describable with a cumulative reward.
- a discount factor used to reduce the influence of actions in the far future (uncertainty of the future)
- Markov Property describes that the future is only dependent on the current state and the action taken.
- A model predicts what will happen next.
- Distributed Models return a probability for each outcome
- Sample Models return a probability for one outcome.
- A trajectory is a sequence of states and actions. It can be deterministic, if it is clear what will happen (given the same state and action) or stochastic, if we know the probabilities of what will happen.
- A policy describes the behavior of an agent given a state . Policies can be deterministic, meaning given a state the policy will always take the same action or stochastic, where an action is taken with a specified probability (e.g. Gaussian).
-
State Value Function predicts the expected cumulative reward to evaluate the quality of a state given the agent follows a policy .
-
The Action-Value Function is the expected cumulative reward given state and taking action .
- Optimal Vale Functions and describe the maximum value over all policies, meaning the MDP is solved once it is known.
- To solve this we can use the Bellman Optimality Equation, which selects the best immediate reward and then recursively follows the optimal value function of the next states with the given probability.
Model-based Reinforcement Learning
Learn a model of the environment from experience and plan or optimize a policy. This model might be transferable to other use cases, is more efficient, can be trained supervised and is usable for Multi-Task RL. Supervised learning can be achieved by optimizing .
We distinguish between Real Experience (RE), sampled from a real environment or Simulated Experience (SE), sampled from a model.
With Open-Loop Control we use the simulated experience to plan the next actions with the model. Finding the optimal Plan can be achieved via sampling, e.g. after training a model, iteratively sample action sequences and select the one with the highest reward. Backpropagation to choose the action is the second way.(Janner et al., 2019)
This approach can fail if there is imprecision in the model, e.g. if the real trajectory differs from the planned. There are two ideas to solving this issue: 1. Retrain the model after some sequences (data aggregation) 2. Replan after each action. This is a closed-loop principle.
Model Predictive Control
Model Predictive Control (MPC) uses both data aggregation and replanning to optimize the model iteratively.
Dyna-style
 **Dyna Style Reinforcement Learning. Grafik adapted from (Zollner et al., 2020) **
**Dyna Style Reinforcement Learning. Grafik adapted from (Zollner et al., 2020) **
Train a Policy through the model.
- Run some policy (e.g. random) and train model
- Sample a state from the real experience (RE). Do not use a random state to prevent distributional shift.
- Simulate transitions with the model using a policy
- Update the policy using step 1 and sample more starting with step 4.
Monte Carlo Tree Search
Using the model to simulate possible actions and by applying the Monte Carlo Tree Search (Coulom, 2006)continuously improve the selection policy. Any tree node is described by the Action-Value function . We use Upper Confidence Tree (UCT) Search to traverse the tree to balance exploration and exploitation. This can be seen in the following formula:
$ U C T(s, a)= \underbrace{\hat{Q}(s, a)}_{\text {exploitation}}+\underbrace{c \sqrt{\frac{\ln N(s)}{N(s, a)}}}_{\text{exploration}}\hat{Q}(s, a)$ the mean action value for a given node and action, the number of visits for a given node Number for given node and action.
The schema of the Monte Carlo Tree Search looks like this:
- Selection. Select the action with the higher UCT Value. If two have the same select one at random
- Expansion. Go to the child node
- Simulation Simulate until you reach a terminal state and get a reward
- Update. By propagating backward count the number of passes at each node and the sum of the reward values.(Coulom, 2006)
- Go back to Step 1
Bibliography
Larry F Abbott. Lapicque’s introduction of the integrate-and-fire model neuron (1907). Brain research bulletin, 50(5-6):303–304, 1999. ↩ 1 2
Les E Atlas, David A Cohn, and Richard E Ladner. Training connectionist networks with queries and selective sampling. In Advances in neural information processing systems, 566–573. 1990. ↩
Guillaume Bellec, Franz Scherr, Elias Hajek, Darjan Salaj, Robert Legenstein, and Wolfgang Maass. Biologically inspired alternatives to backpropagation through time for learning in recurrent neural nets. arXiv preprint arXiv:1901.09049, 2019. ↩
Kristin P Bennett and Ayhan Demiriz. Semi-supervised support vector machines. In Advances in Neural Information processing systems, 368–374. 1999. ↩ 1 2
Avrim Blum and Tom Mitchell. Combining labeled and unlabeled data with co-training. In Proceedings of the eleventh annual conference on Computational learning theory, 92–100. 1998. ↩ 1 2
Claudia Clopath and Wulfram Gerstner. Voltage and spike timing interact in stdp–a unified model. Frontiers in synaptic neuroscience, 2:25, 2010. ↩
Rémi Coulom. Efficient selectivity and backup operators in monte-carlo tree search. In International conference on computers and games, 72–83. Springer, 2006. ↩ 1 2
Peter U Diehl and Matthew Cook. Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Frontiers in computational neuroscience, 9:99, 2015. ↩
Donald Olding Hebb. The organization of behavior: A neuropsychological theory. Psychology Press, 2005. ↩
Geoffrey E Hinton. Training products of experts by minimizing contrastive divergence. Neural computation, 14(8):1771–1800, 2002. ↩
Geoffrey E Hinton, Simon Osindero, and Yee-Whye Teh. A fast learning algorithm for deep belief nets. Neural computation, 18(7):1527–1554, 2006. ↩
Alan L Hodgkin and Andrew F Huxley. A quantitative description of membrane current and its application to conduction and excitation in nerve. The Journal of physiology, 117(4):500, 1952. ↩
Eugene M Izhikevich. Simple model of spiking neurons. IEEE Transactions on neural networks, 14(6):1569–1572, 2003. ↩
Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to trust your model: model-based policy optimization. In Advances in Neural Information Processing Systems, 12519–12530. 2019. ↩
Renaud Jolivet, J Timothy, and Wulfram Gerstner. The spike response model: a framework to predict neuronal spike trains. In Artificial neural networks and neural information processing—ICANN/ICONIP 2003, pages 846–853. Springer, 2003. ↩
Jacques Kaiser, Michael Hoff, Andreas Konle, Juan Camilo Vasquez Tieck, David Kappel, Daniel Reichard, Anand Subramoney, Robert Legenstein, Arne Roennau, Wolfgang Maass, and others. Embodied synaptic plasticity with online reinforcement learning. Frontiers in Neurorobotics, 13:81, 2019. ↩
Jacques Kaiser, Hesham Mostafa, and Emre Neftci. Synaptic plasticity dynamics for deep continuous local learning (decolle). Frontiers in Neuroscience, 14:424, 2020. ↩ 1 2
David D Lewis and William A Gale. A sequential algorithm for training text classifiers. In SIGIR’94, 3–12. Springer, 1994. ↩
Adam H Marblestone, Greg Wayne, and Konrad P Kording. Toward an integration of deep learning and neuroscience. Frontiers in computational neuroscience, 10:94, 2016. ↩
Henry Markram, Wulfram Gerstner, and Per Jesper Sjöström. A history of spike-timing-dependent plasticity. Frontiers in synaptic neuroscience, 3:4, 2011. ↩
Timothée Masquelier, Rudy Guyonneau, and Simon J Thorpe. Spike timing dependent plasticity finds the start of repeating patterns in continuous spike trains. PloS one, 3(1):e1377, 2008. ↩
Emre O Neftci, Hesham Mostafa, and Friedemann Zenke. Surrogate gradient learning in spiking neural networks. IEEE Signal Processing Magazine, 36:61–63, 2019. ↩
Matthew Richardson and Pedro Domingos. Markov logic networks. Machine learning, 62(1-2):107–136, 2006. ↩ 1 2
Burr Settles. Active learning literature survey. Computer Sciences Technical Report 1648, University of Wisconsin–Madison, 2009. ↩
H Sebastian Seung, Manfred Opper, and Haim Sompolinsky. Query by committee. In Proceedings of the fifth annual workshop on Computational learning theory, 287–294. 1992. ↩ 1 2
Friedemann Zenke and Surya Ganguli. Superspike: supervised learning in multilayer spiking neural networks. Neural computation, 30(6):1514–1541, 2018. ↩ 1 2
J Marius Zöllner, Karam Daaboul, and Karl Kurzer. Vorlesungsfolien maschinelles lernen ii - fortgeschrittene verfahren. July 2020. ↩
#active learning #ai #artificial intelligence #co-learning #exam #kit #lecture #lecture-notes #machine learning #semi-supervised #summary #Vapnik