Safety and Security for Neuronal Networks
Terminology
- Robustness. Insensitivity to deviations from the underlying assumptions
- Saftey. Robustness to natural deviations (malfunctions)
- Security. Robustness to intended malicious artificially crafted input
- Verifiable AI - methods to ensure/prove the correctness of AI
- Explainable AI (XAI)- methods to make the results of AI understandable for humans
Insufficiencies of Deep Neuronal Networks
Insufficiencies are systematic latent weaknesses
- Lack of Generalization. Input is different from training → Adversarial Attacks
- Lack of Explainability. Explain how what the AI learned and how it came to its decision
- Lack of Plausibility.
Interpretability
Interpretability [is] the ability to explain or to present in understandable terms to a human. (DoshiVelez and Kim, 2017)
Especially for critical systems (e.g. autonomous driving), we need to make sure that all edge cases are in the problem statement (Completeness).
- Transparent interpretability: How does the model work? This can be approached at different abstraction level model, components, or algorithmic level.
- Post-Training Interpretability: What could the model tell me? Based on explanations.
→ The Goal is to have an explanation that is human-understandable. (Molnar, 2019) From this goal we can derive properties that an explanation method should have:
- Expressive Power: Language and Structure are understandable.
- Translucency: The amount of (parameter) knowledge the method needs.
- Portability: Transfer of explanations is possible.
- Algorithmic Complexity: The computational effort needed to generate the explanation. (Molnar, 2019)
And to make the method human-friendly, answers should answer the why-question. So good properties for explanations include
- Contrastive. Why this prediction and not another?
- Selective. Even if many reasons influence the prediction, only give back a couple.
- Social. Explanations are part of a communication
- Focus on the abnormal. Abnormal things should always be included
- Truthful. Machine Learning needs fidelity
- Consistent. Should conform to prior beliefs
- Probable and General. A generalized explanation is better than a rare cause.
Feature Visualization & Importance
The goal of Feature Visualization is to show the user what parts of the input image are most important for the classification. This can be seen as “Where does the network look most?”
Activation Maps
Activation or Feature Maps visualize the filters of Convolutional Neuronal Networks. The idea is to create an image with random pixels and for each layer, you are interested in computing the gradients and update the pixel values to maximize the activation output.
Saliency Maps
Saliency maps help to understand the contribution of certain pixels in certain regions to the overall output.(Simonyan et al., 2013)
Class Activation Maps
A class activation map for a particular category indicates the discriminative image regions used by the CNN to identify that category. (Zhou et al., 2016)
The Activation map preceding the Global Average Pooling (GAP) Layer is a feature representation of the target but in space.
Gradient Class Activation Maps
Gradient Class Activation Maps (Grad-CAM) uses additional Gradient in combination with GAP.
Occlusion Sensitivity
By covering parts of the input image with grey patches (of increasing size) we can learn whether a feature map is sensitive to a specific part of the image. (Zeiler and Fergus, 2014) The common issue is that the background is learned instead of the object.
SHAPley Values
Idea from Game Theory to find out how much each feature contributed to the final output. The Shapley value is the average of all the marginal contributions to all possible coalitions.
Local interpretable model-agnostic explanations (LIME)
Local interpretable model-agnostic explanations (LIME) by Ribeiro et al. (2016) is a model agnostic way to explain a prediction. The instance requiring explanation is perturbed and get the predictions of our model. We then learn a second linear model with which we get the superpixel with the highest importance.
→ I like this explanation or this video.
Adversarial Attacks
Taxonomy
based on the access level
- White Box - full knowledge of the model (parameters, structure…) → Gradient-based attacks
- Black Box - no knowledge of the model → Gradient-free attacks
- Grey Box - some knowledge (e.g. by transfer from another model)
based on goal
- Untargetet - output can be any class
-
Targeted - output is of a specific class
-
Adversarial example (AE) – input pattern that is generated to fool machine learning algorithm
- Perturbate ( in an allowed/reasonable perturbation set ) a given example in a way that maximizes the loss
Methods
Fast Gradient Sign Method
The Fast Gradient Sign Method (FGSM) by Goodfellow et al. (2014) adds noise to move in the direction of the gradient (untargeted attack) or opposite towards the target class (targeted attack). The parameters control the size (visibility) of the perturbation.
Projected Gradient Descent
Projected Gradient Descent iteratively takes gradient steps as described in FGSM
Carlini & Wagner Attack
The Carlini & Wagner Attack (C&W) starts with an adverserial loss with the logits returned and a confidence parameter.
The Optimization Problem is now subject to . The Optimization problem is to keep the change small and get a negative , which happens when is missclassified. The constraint is for the pixel values of the image to be valid. (Carlini and Wagner, 2016)
Zeroth Order Optimization
Zeroth Order Optimization (ZOO) is a gradient-free attack, meaning it works for black-box models, with access to just the scores. It has the same approach as the Carlini & Wagner Attack but infers the gradients form a large number of outputs. (Chen et al., 2017)
Boundary Attacks
Boundary Attacks by Brendel et al. (2017) (gradient-free black-box approach) search for the boundary between classes. The attacks start by choosing a point away from the clean image and then performing a binary search to find the boundary. Afterward, it follows the boundary to the closest point from the original image. Check out the visualization by the author.
Real World Attacks
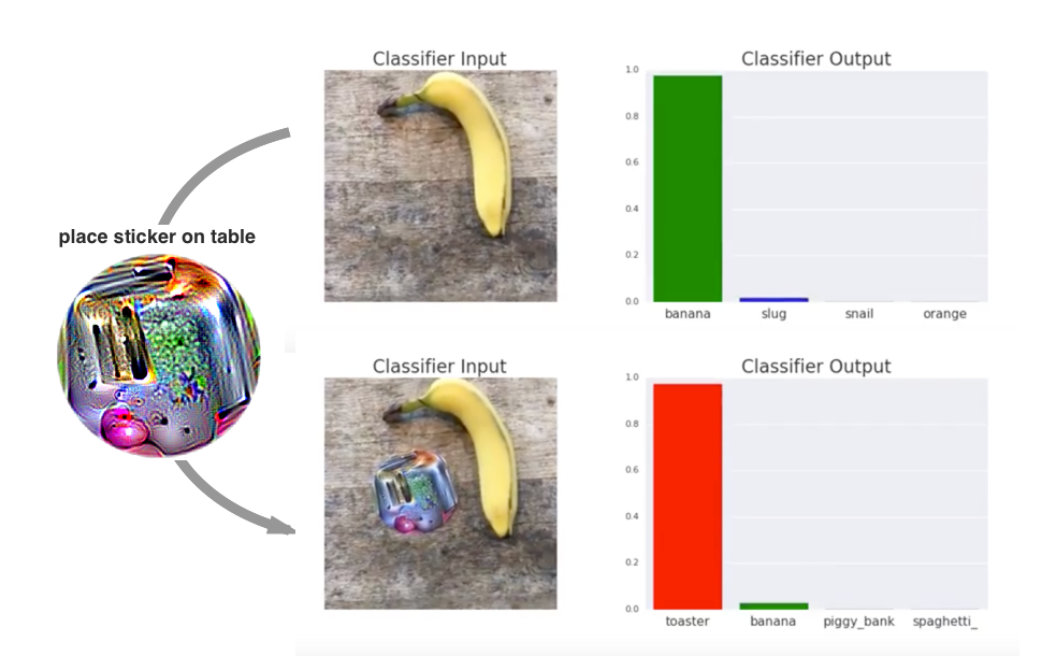 Real-World Attacks work by printing out a patch of perturbation (Brown et al., 2017) (Sharif et al., 2016).
Real-World Attacks work by printing out a patch of perturbation (Brown et al., 2017) (Sharif et al., 2016).
Defences
Increasing robustness
- Gradient Masking. Prevents a model from revealing meaningful gradients (e.g. Random Operations, shattered gradients)
- Adversarial Training. Add adversarial examples to the training. Model is vulnerable to unseen attacks
- Defense Distillation. (Papernot et al., 2016) Use two networks, one trained on data and one on the output probabilities of the first networks.
Detecting Adversarial Examples
- Naïve Approaches. Find differences between clean inputs and adversarial examples (e.g. PCA)
- Detector Networks. Add a subnetwork classifier
- Feature Squeezing. Compare predictions between squeezed (color reduction, spatial smoothing) and the unsqueezed image.
Bibliography
Wieland Brendel, Jonas Rauber, and Matthias Bethge. Decision-based adversarial attacks: reliable attacks against black-box machine learning models. arXiv preprint arXiv:1712.04248, 2017. ↩
Tom B Brown, Dandelion Mané, Aurko Roy, Martín Abadi, and Justin Gilmer. Adversarial patch. arXiv preprint arXiv:1712.09665, 2017. ↩
Nicholas Carlini and David A. Wagner. Towards evaluating the robustness of neural networks. CoRR, 2016. URL: http://arxiv.org/abs/1608.04644, arXiv:1608.04644. ↩
Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. Zoo: zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, 15–26. 2017. ↩
Finale Doshi-Velez and Been Kim. Towards a rigorous science of interpretable machine learning. arXiv preprint arXiv:1702.08608, 2017. ↩
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014. ↩
Christoph Molnar. Interpretable Machine Learning. GitHub, 2019. \url https://christophm.github.io/interpretable-ml-book/. ↩ 1 2 3
Nicolas Papernot, Patrick McDaniel, Xi Wu, Somesh Jha, and Ananthram Swami. Distillation as a defense to adversarial perturbations against deep neural networks. In 2016 IEEE Symposium on Security and Privacy (SP), 582–597. IEEE, 2016. ↩
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. "why should i trust you?" explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, 1135–1144. 2016. ↩
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034, 2013. ↩
Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In European conference on computer vision, 818–833. Springer, 2014. ↩
Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2921–2929. 2016. ↩
#adverserial #artificial intelligence #attack #explainability #interpretability #machine learning #neuronal networks #robustness #safety #security